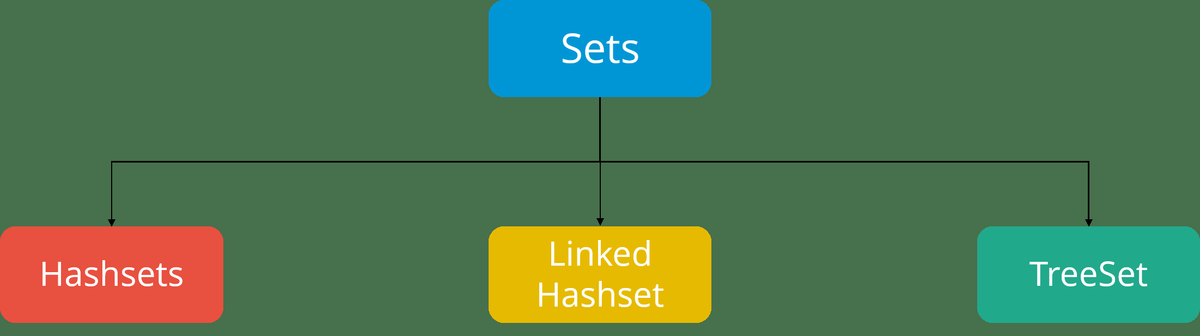
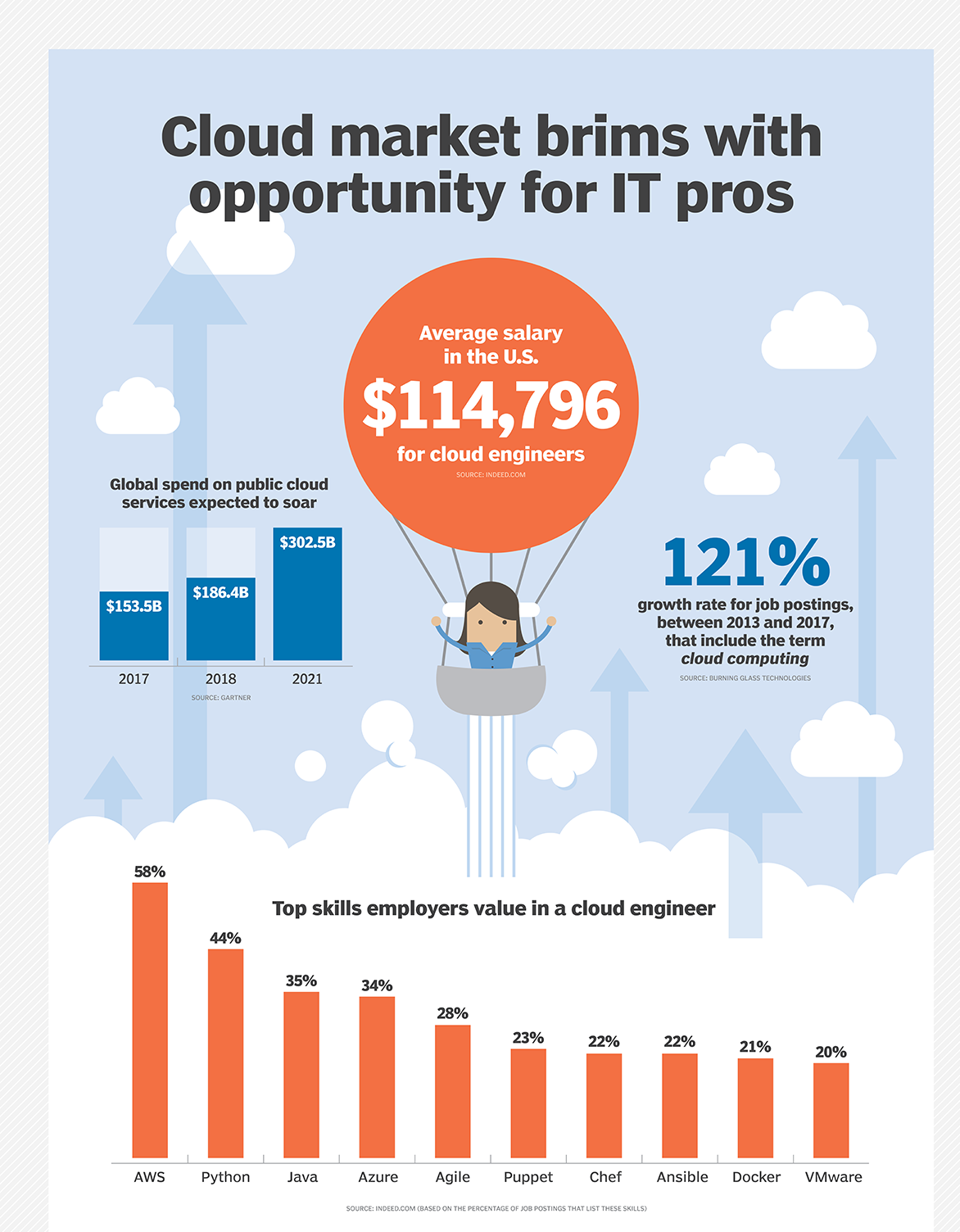
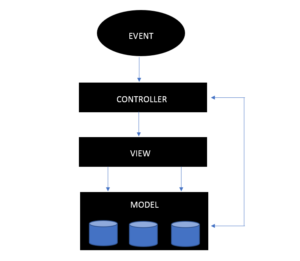
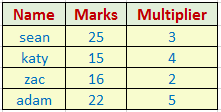
Jak spustit skripty podregistrů?
Toto je návod, jak spouštět skripty Hive. Spuštění tohoto skriptu sníží čas a úsilí, které jsme vynaložili na ruční psaní a provádění každého příkazu.

Toto je návod, jak spouštět skripty Hive. Spuštění tohoto skriptu sníží čas a úsilí, které jsme vynaložili na ruční psaní a provádění každého příkazu.
Přečtěte si tento blogový příspěvek a vytvořte svůj první skript Apache Pig. Skripty Apache Pig se používají ke společnému provádění sady příkazů Apache Pig.
Programování prasat: Apache Pig Script s UDF v režimu HDFS. Zde je blogový příspěvek ke spuštění skriptu Apache Pig s UDF v režimu HDFS ...
Tento příspěvek popisuje Hadoop Map boční připojení vs. připojit se. Zjistěte také, co je zmenšení mapy, připojení tabulky, připojení strany, výhody použití operace připojení na straně mapy v Hive
Víte, jak přidat nebo odebrat uzly v clusteru Hadoop? Zde je blogový příspěvek - Uzly pro uvedení do provozu a vyřazení z provozu v klastru Hadoop.
Tento blog popisuje všechny užitečné příkazy prostředí Hadoop. Spolu s příkazy Hadoop Shell má také snímky obrazovky, které usnadňují učení. Číst dál!
Předpokládá se, že velká data a hadoop budou budoucností systému pro správu dat. Big data budou pro lidi přecházející z Mainframe na Big Data Hadoop.
Tento příspěvek popisuje operátory v Apache Pig. Podívejte se na tento příspěvek pro Operátory v Apache Pig: Část 1 - Relační operátoři.
Tento příspěvek pojednává o HBase a poznatcích o HBase Architecture. Rovněž pojednává o komponentách Hbase, jako je Master, Region server a Zoo keeper a o tom, jak je používat.
Tento příspěvek popisuje Apache Pig UDF - Eval, Aggregate & Filter Functions. Podívejte se na funkce Eval, Aggregate & Filter Functions.
Tento příspěvek popisuje funkce Apache Pig UDF - Load. (Apache Pig UDF: Part 2). Podívejte se na funkce načítání Apache Pig UDF.
Tento příspěvek popisuje informace o Apache Pig UDF - funkce obchodu. (Apache Pig UDF: Část 3). Podívejte se na funkce obchodu Apache Pig UDF.
V tomto blogu se dozvíme o instalaci Apache Hive na Ubuntu a koncepcích kolem Hadoop Hive, Hive sql, Hive databáze, Hive serveru a instalace Hive.
Tento příspěvek popisuje, jak se velká data používají k posílení marketingových schopností v telekomunikačním průmyslu. Čtěte dále a dozvíte se více o Big Data a telekomunikačním průmyslu.
Zjistěte, proč se inženýr testování softwaru musí naučit Big Data a Hadoop a jak mu školení Big Data a certifikace Hadoop mohou pomoci získat ty nejlepší Big Data úlohy.
Tento příspěvek pojednává o ukázce Proof of Concept pro HBase. Můžete najít jasné vysvětlení konceptu, abyste lépe porozuměli HBase.
Oracle to HDFS using Sqoop - Podívejte se na kroky pro Oracle to HDFS pomocí Sqoop.
Big Data mohou řešit potíže, kterým čelí velké organizace. Níže jsou uvedeny příklady případů použití velkých dat Big Data, které se používají k řešení problémů, kterým čelí.
Apache Storm je populární díky svým funkcím zpracování v reálném čase a byl implementován právě z tohoto důvodu. Zde je několik případů použití Apache Storm.
Správci Hadoopu je naléhavě potřeba, protože organizace rychle využívají Hadoop a jakýkoli klastr větší než 20–30 uzlů vyžaduje administrátora na plný úvazek.