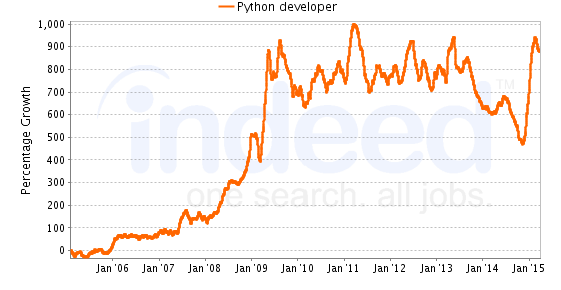
Spark vs Hadoop: Který je nejlepší rámec velkých dat?
Tento příspěvek na blogu hovoří o apache spark vs hadoop. Poskytne vám představu o tom, který je správný rámec Big Data pro výběr v různých scénářích.

Tento příspěvek na blogu hovoří o apache spark vs hadoop. Poskytne vám představu o tom, který je správný rámec Big Data pro výběr v různých scénářích.
Tento blog vám pomůže pochopit, jak nainstalovat a nastavit plugin sbteclipse s podrobnými pokyny pro spuštění aplikace Scala v prostředí Eclipse IDE.
Tento příspěvek na blogu vysvětluje, proč musíte začít s Apache Spark po Hadoopu a proč učení Spark po zvládnutí hadoopu může dělat zázraky pro vaši kariéru!
Tento výukový program Apache Drill vám poskytne všechny informace, které potřebujete, abyste mohli začít s vyhledávacím strojem Apache Drill, použití s Hadoop, Big Data & Apache Spark.
Tento blog Spark Hadoop vám řekne vše, co potřebujete vědět o Apache Spark combineByKey. Najděte průměrné skóre na studenta pomocí metody combineByKey.
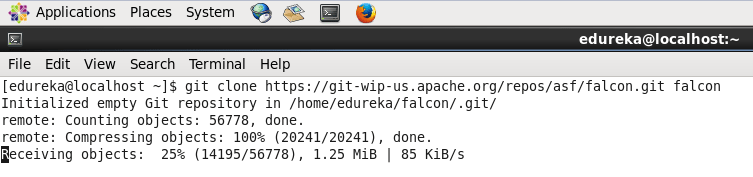
Apache Falcon je nová platforma pro správu dat pro ekosystém Hadoop, která zjednodušuje připojení zpracování krmiva a správu krmiva v klastrech hadoop. Naučte se, jak to nastavit.
Tento blog Apache Spark podrobně vysvětluje akumulátory Spark. Naučte se použití akumulátoru Spark s příklady. Akumulátory jisker jsou jako počitadla Hadoop Mapreduce.
V tomto blogu se dozvíte vše o Apache Flink a nastavení klastru Flink. Flink podporuje v reálném čase a dávkové zpracování a je technologií Big Data, kterou musíte pro Big Data Analytics sledovat.
Tento příspěvek na blogu pojednává o distribuovaném ukládání do mezipaměti s proměnnými všesměrového vysílání a umožňuje vám začít efektivně distribuovat velké hodnoty v programování Spark.
Certifikace CCA a CCP od společnosti Cloudera nahradily zkoušky CCDH a CCSHB. Tento blog vám řekne vše, co potřebujete vědět o nových certifikacích.
Tento blogový příspěvek pojednává o stavových transformacích s vytvářením oken ve Spark Streaming. Naučte se vše o sledování dat napříč dávkami pomocí stavových D-streamů.
Tento blogový příspěvek pojednává o stavových transformacích ve Spark Streaming. Naučte se vše o kumulativním sledování a dovednostech pro kariéru Hadoop Spark.
Technologie Hadoop a Big Data znamenají revoluci v analytice zdravotní péče. Tento blog o velkých datech ve zdravotnictví pojednává o tom, jak může analýza velkých dat vylepšit lékařskou péči.
Tento příspěvek na blogu o streamování Hadoop je podrobným průvodcem, jak se naučit psát program Hadoop MapReduce v Pythonu pro zpracování obrovského množství velkých dat.
Tento blog o výuce velkých dat vám poskytne kompletní přehled o velkých datech, jejich charakteristikách, aplikacích a výzvách s velkými daty.
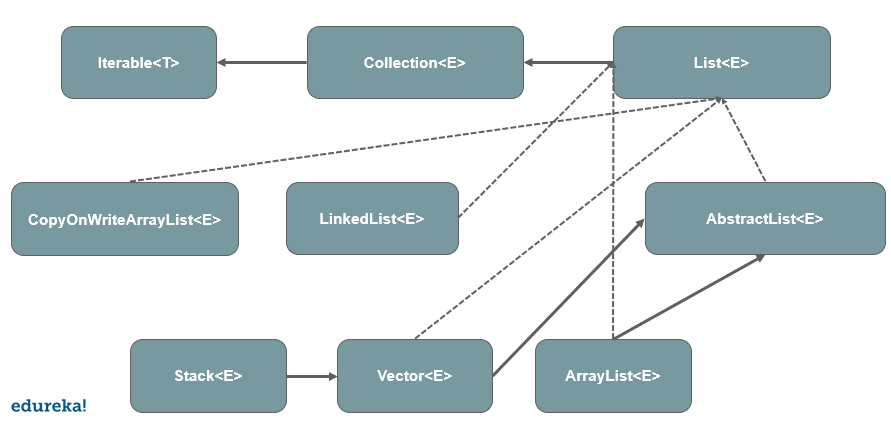
Tento blog s výukou HDFS vám pomůže porozumět HDFS nebo Hadoop Distributed File System a jeho funkcím. Stručně také prozkoumáte jeho základní součásti.
V tomto výukovém programu Splunk pochopte rozdíly mezi Splunk vs. ELK vs. Sumo Logic a určete, který z těchto nástrojů vám nejlépe vyhovuje.
V tomto blogu Případ použití Splunk pochopíte, jak společnost Domino's Pizza použila Splunk k získání informací o chování spotřebitelů. A formulaci jejich obchodních strategií.
Tento kurz je krok za krokem instalací clusteru Hadoop a jeho konfigurací na jednom uzlu. Všechny kroky instalace Hadoop jsou pro stroj CentOS.
Tento blog hovoří o různých příkazech HDFS, jako jsou fsck, copyFromLocal, expunge, cat atd., Které se používají ke správě systému souborů Hadoop.